 Wert von Citizen Science Daten und limitierten anderen Informationen für die Kalibrierung eines hydrologischen Modells
Wert von Citizen Science Daten und limitierten anderen Informationen für die Kalibrierung eines hydrologischen Modells
Ich heisse Franziska und ich arbeite als “Community Managerin” im CrowdWater Projekt. Auch meine Masterarbeit habe ich im Rahmen von CrowdWater geschrieben und im Juni 2022 eingereicht. Was ich gemacht habe und was dabei herauskam, stelle ich auf dieser Seite vor. Meine ganze Arbeit als PDF stelle ich hier zur Verfügung.
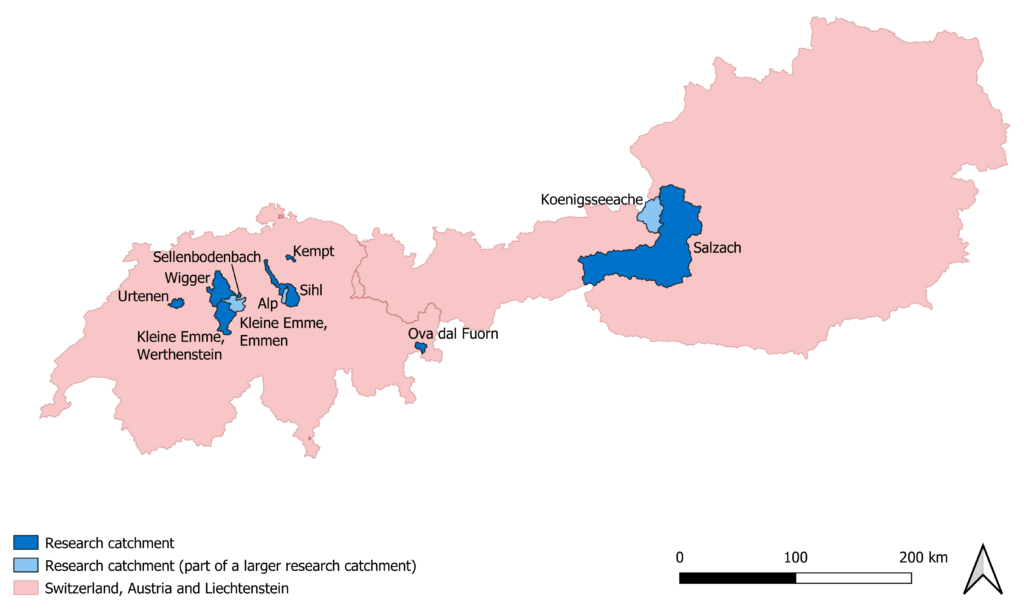
Für meine Masterarbeit habe ich hydrologische Modellierungen gemacht. Dabei habe ich Beobachtungen der Wasserstandsklasse in der Kategorie «virtuelle Messlatte» aus elf Einzugsgebieten in der Schweiz und in Österreich verwendet. Die elf Einzugsgebiete sind auf der unten abgebildeten Karte dargestellt. Von all diesen Einzugsgebieten sind offiziell gemessene Abflussdaten verfügbar, welche ich zur Kontrolle meiner Ergebnisse verwenden konnte. Ziel meiner Arbeit war es, mehr über den Wert der Beobachtungen für die hydrologische Modellierung herauszufinden. Dabei habe ich die Citizen Science Daten in Kombination mit anderen Informationen über den Abfluss verwendet.
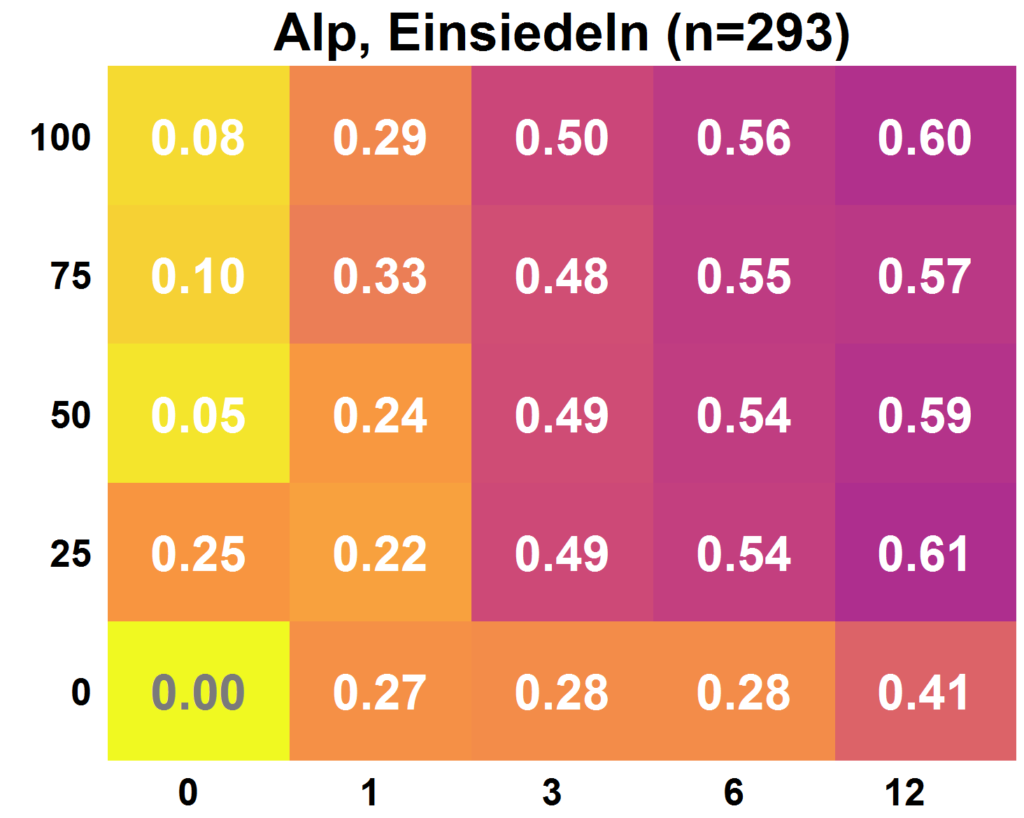
Für jedes der Einzugsgebiete hatte ich eine bestimmte Anzahl an Wasserstandsklassen-Beobachtungen zur Verfügung. Diese habe ich mit einer beschränkten Anzahl von Abflussmessungen, welche regelmässig über das Jahr verteilt sind, kombiniert. So habe ich 24 verschiedene Szenarien der Datenverfügbarkeit erhalten, nämlich alles möglichen Kombinationen aus
- 0%, 25%, 50%, 75% und 100% der verfügbaren Citizen Science Daten, sowie
- 0, 1, 3, 6, 12 Abflussmessungen pro Jahr.
Diese 24 Szenarien bildeten den Basis-Ansatz für die Analysen des Werts der Daten: Ich habe das HBV Modell, ein Modell zur Simulierung von Abfluss in einem Einzugsgebiet, für jedes meiner Einzugsgebiete mit den 24 verschiedenen Szenarien kalibriert. So habe ich Parametersets erhalten, mit welchen ich den Abfluss in einem Einzugsgebiet simulieren konnte. Diesen simulierten Hydrographen (Zeitreihe des simulierten Abflusses) habe ich mit dem an der jeweiligen Messstelle gemessenen Hydrographen verglichen. Dieser Vergleich ermöglichte eine Aussage darüber, wie gut das Modell den tatsächlichen Abfluss simulieren kann. Diese Modellgüte kann mit einer Zahl ausgedrückt werden. Je höher diese Zahl, desto besser stimmen der simulierte und der gemessene Abfluss überein.
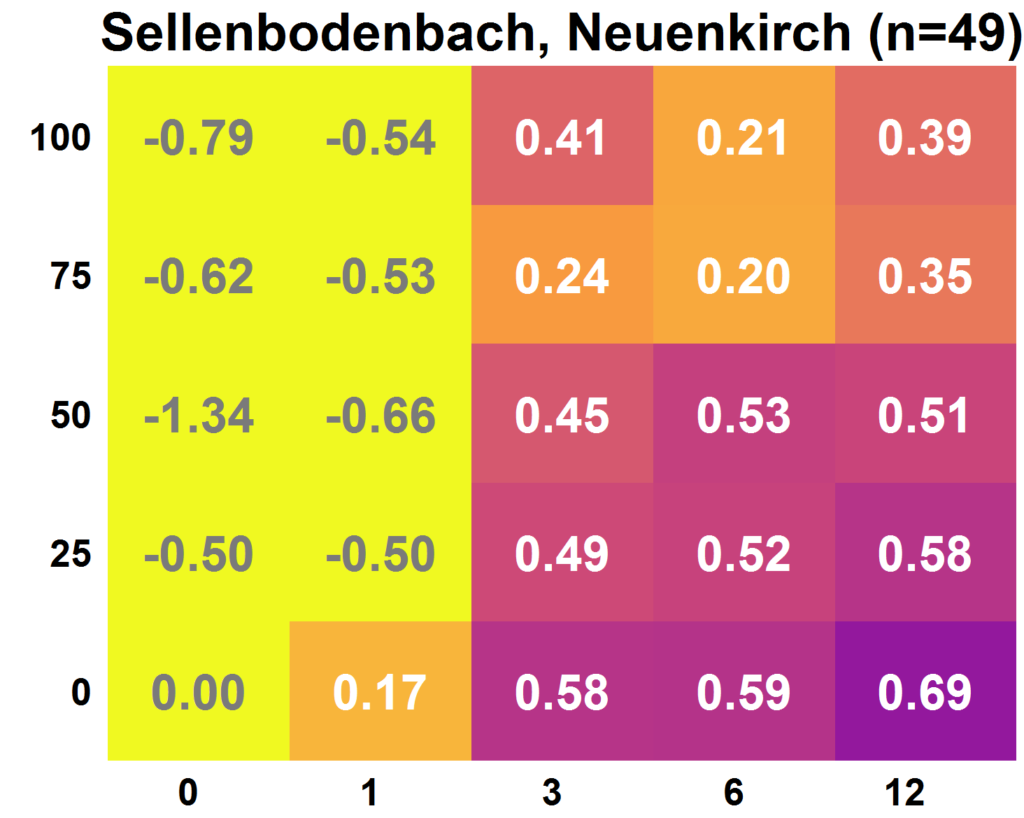
Die untenstehende Graphik auf der linken Seite zeigt exemplarisch die Resultate für die Alp in Einsiedeln. Es ist gut sichtbar, das die Modellgüte mit mehr Daten tendenziell höher ausfällt: Die Felder werden dunkler (was einem höheren Wert entspricht), je weiter oben und je weiter rechts sich das Feld befindet. Die Anzahl der Abflussmessungen nimmt von links nach rechts zu. Der Anteil an verwendeten Citizen Science Beobachtungen nimmt von unten nach oben zu. Zufällig gewählte Parametersets resultieren in einer Modellgüte von 0, eine perfekte Simulation des Abflusses resultiert in einer Modellgüte von 1. Die Resultate waren nicht für alle Einzugsgebiete so deutlich. Die Menge der vorhandenen Citizen Science Beobachtungen und deren Genauigkeit hatten einen Einfluss darauf, ob die Verwendung von Citizen Science Beobachtungen zu einem Mehrwert führten oder nicht. Beispielsweise am Sellenbodenbach in Neuenkirch waren die Kalibrierungen auf Basis von 12 Abflussmessungen erfolgreicher, als wenn zusätzlich Citizen Science Beobachtungen verwendet wurden.
Den oben beschriebenen Basis-Ansatz habe ich auf verschiedene Arten modifiziert, um mehr Informationen über den Wert verschiedener Daten zu erhalten. Die zusätzliche Verwendung einer Schätzung für den mittleren Abfluss im Einzugsgebiet führte zu einer deutlichen Verbesserung der Resultate. In Einzugsgebieten mit eher ungenauen Beobachtungen der Wasserstandsklassen konnte weiter eine Verbesserung der Resultate erreicht werden, indem anstelle von Wasserstandsklassen die gemessenen Wasserstände zu den gleichen Zeitpunkten verwendet wurden.
In einem letzten Ansatz habe ich für die Königsseeache, die Salzach, die Urtene und die Alp anstelle der Wasserstandsklassen aus der App die resultierenden Medianwerte aus dem CrowdWater Spiel verwendet. Für die Alp, an welcher die Wasserstandsklassen im Spiel verbessert wurden (für die Königsseeache und die Salzach war keine deutliche Verbesserung zu erkennen, für die Urtene waren die Werte aus der App besser als jene aus dem Spiel), wurden die Resultate dadurch verbessert, insbesondere wenn die Kalibrierung hauptsächlich auf Citizen Science Daten beruhte.
Ich bedanke mich bei allen für das Mitmachen beim CrowdWater Projekt und damit für die Ermöglichung meiner Masterarbeit. Ich habe unglaublich gerne mit den Daten aus der CrowdWater App und dem CrowdWater Spiel gearbeitet! Über Fragen und Kommentare zu meiner Masterarbeit freue ich mich! Ich bin unter info@crowdwater.ch erreichbar.