 Valeur des données de la science citoyenne et des autres informations limitées pour la calibration d’un modèle hydrologique
Valeur des données de la science citoyenne et des autres informations limitées pour la calibration d’un modèle hydrologique
Je m’appelle Franziska et je travaille comme « community manager » dans le projet CrowdWater. J’ai également rédigé mon thèse de master dans le cadre de CrowdWater et je l’ai remise en juin 2022. Je présente sur cette page ce que j’ai fait et ce qui en est ressorti. Je mets à disposition l’ensemble de mon travail en format PDF ici.
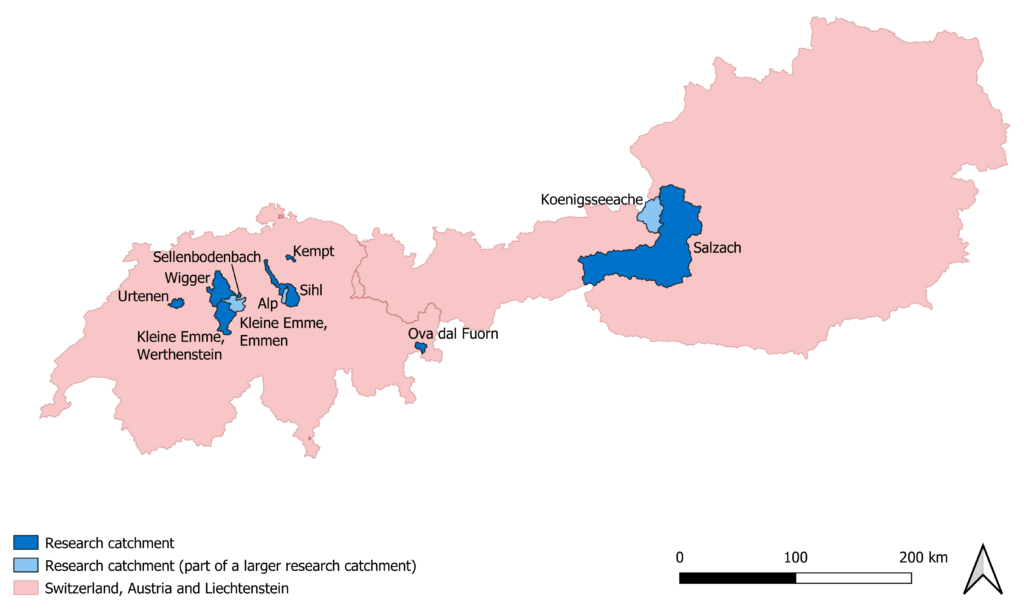
Pour mon thèse de master, j’ai fait des modélisations hydrologiques. Pour ce faire, j’ai utilisé des observations de la classe de niveau d’eau dans la catégorie « échelle de mesure virtuelle » de onze bassins versants en Suisse et en Autriche. Les onze bassins versants sont représentés sur la carte ci-dessous. Des données de débit mesurées officiellement sont disponibles pour tous ces bassins versants et j’ai pu les utiliser pour contrôler mes résultats. L’objectif de mon travail était d’en savoir plus sur la valeur des observations pour la modélisation hydrologique. Pour ce faire, j’ai utilisé les données de la science citoyenne en combinaison avec d’autres informations sur le débit.
Pour chacun des bassins versants, je disposais d’un certain nombre d’observations de classes de niveau d’eau. Je les ai combinées avec un nombre limité de mesures de débit, régulièrement réparties sur l’année. J’ai ainsi obtenu 24 scénarios différents de disponibilité des données, à savoir toutes les combinaisons possibles de
- 0%, 25%, 50%, 75% et 100% des données de science citoyenne disponibles, et
- 0, 1, 3, 6, 12 mesures de débit par an.
Ces 24 scénarios ont constitué l’approche de base pour les analyses de la valeur des données : J’ai calibré le modèle HBV, un modèle de simulation de l’écoulement dans un bassin versant, pour chacun de mes bassins versants avec les 24 scénarios différents. J’ai ainsi obtenu des ensembles de paramètres avec lesquels j’ai pu simuler le débit dans un bassin versant. J’ai comparé cet hydrogramme simulé (série temporelle du débit simulé) avec l’hydrogramme mesuré à la station de mesure correspondante. Cette comparaison a permis de déterminer la qualité du modèle pour simuler le débit réel. Cette qualité du modèle peut être exprimée par un chiffre. Plus ce chiffre est élevé, plus le débit simulé et le débit mesuré concordent.
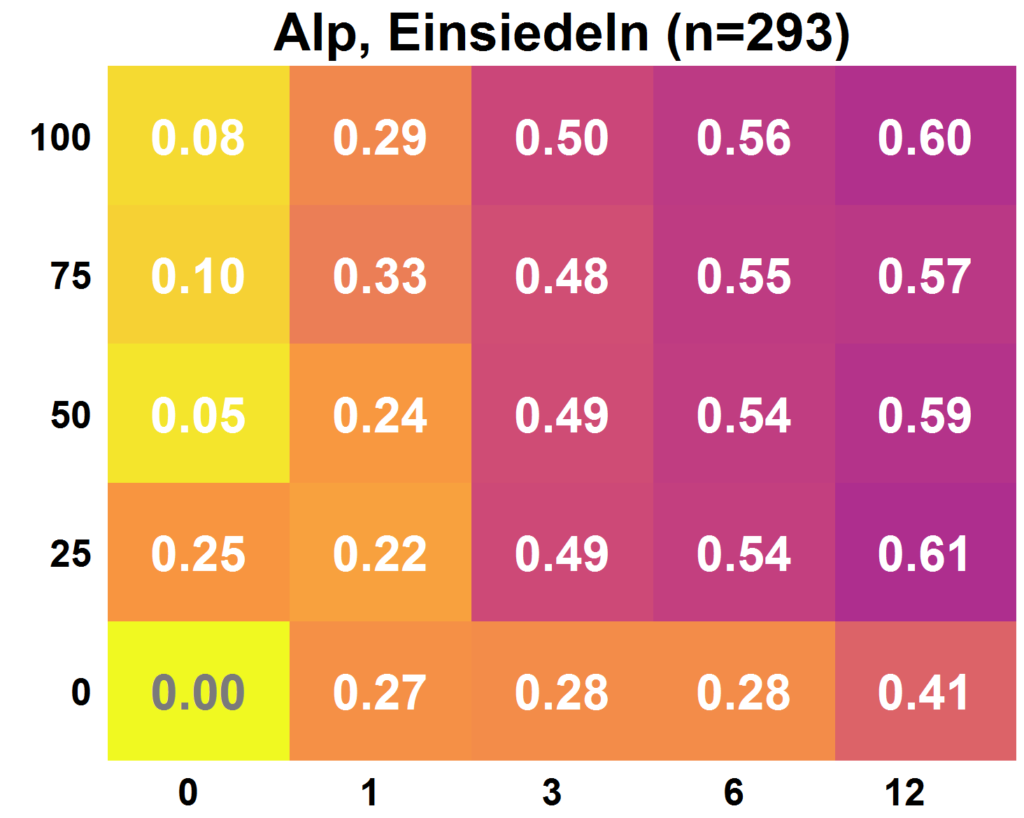
Le graphique de gauche ci-dessous montre à titre d’exemple les résultats pour l’Alp
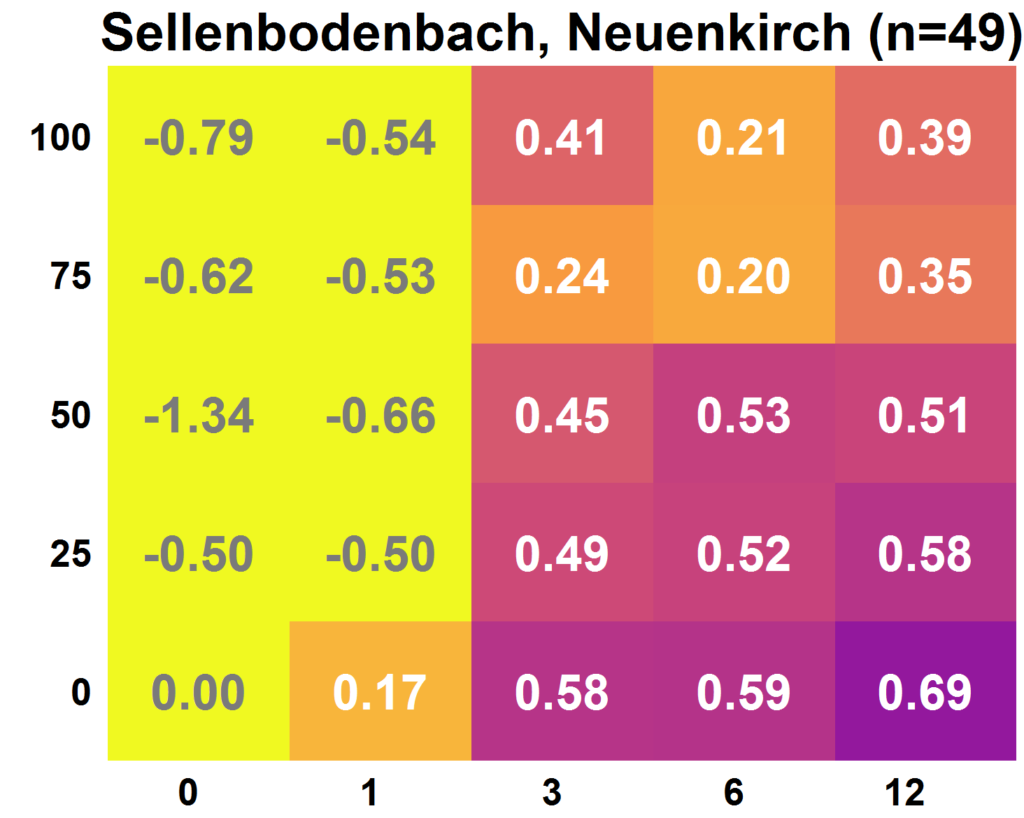
à Einsiedeln. Il est bien visible que la qualité du modèle a tendance à être plus élevée avec plus de données : les champs deviennent plus sombres (ce qui correspond à une valeur plus élevée) plus le champ se trouve en amont et à droite. Le nombre de mesures de débit augmente de gauche à droite. La proportion d’observations de science citoyenne utilisées augmente de bas en haut. Les jeux de paramètres choisis au hasard donnent une qualité de modèle de 0, une simulation parfaite du débit donne une qualité de modèle de 1. Les résultats n’étaient pas aussi clairs pour tous les bassins versants. La quantité d’observations de la science citoyenne disponibles et leur précision ont eu une influence sur le fait que l’utilisation d’observations de la science citoyenne a conduit à une valeur ajoutée ou non. Par exemple, pour le Sellenbodenbach à Neuenkirch, les calibrages basés sur 12 mesures de débit ont été plus efficaces que si des observations de la science citoyenne avaient été utilisées en plus.
J’ai modifié l’approche de base décrite ci-dessus de différentes manières afin d’obtenir plus d’informations sur la valeur de différentes données. L’utilisation supplémentaire d’une estimation du débit moyen dans le bassin versant a conduit à une nette amélioration des résultats. Dans les bassins versants où les observations des classes de niveau d’eau étaient plutôt imprécises, une autre amélioration des résultats a pu être obtenue en utilisant les niveaux d’eau mesurés aux mêmes moments au lieu des classes de niveau d’eau.
Dans une dernière approche, j’ai utilisé les valeurs médianes résultantes du jeu CrowdWater pour la Koenigsseeache, la Salzach, l’Urtene et l’Alp au lieu des classes de niveau d’eau de l’application. Pour l’Alp, où les classes de niveau d’eau ont été améliorées dans le jeu (pour la Koenigsseeache et la Salzach, aucune amélioration significative n’a été constatée, et pour l’Urtene, les valeurs de l’application étaient meilleures que celles du jeu), les résultats s’en sont trouvés améliorés, en particulier lorsque la calibration reposait principalement sur des données de la science citoyenne.
Je remercie tout le monde d’avoir participé au projet CrowdWater et d’avoir ainsi rendu possible mon projet de master. J’ai adoré travailler avec les données de l’application CrowdWater et du jeu CrowdWater ! Je me réjouis de recevoir vos questions et commentaires sur mon projet ! Vous pouvez me joindre à l’adresse info@crowdwater.ch.